Machine-Learned Classification and Semantic Topic Tagging
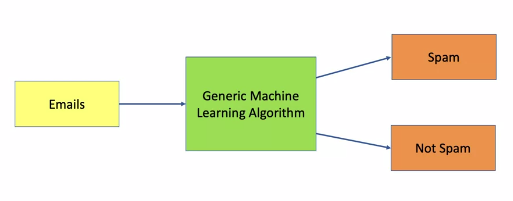
A machine learning classification is a subset of what is called supervised machine learning. Supervised machine learning is the search for algorithms that reason from externally supplied instances to produce general hypotheses, which then make predictions about future instances.
Supervised machine learning is taking intelligence that we have from before and then applying that to predict various things in the future.
One of the most common tasks for supervised machine learning is this task of classification, which is the process of applying meaningful labels to data to help make sense of that data. Supervised machine leaning for classification can be applied to text, especially when the goal is to classify (or categorize) text according to a predefined goal.
Supervised ML for classification
Steps for supervised ML for Classification (Text, in particular)
1. Identify required data and pre-process the data (tokenization, normalization, etc.)
2. Determine which part of the data will be used as the training set from which the computer learns patterns (each data point must be labelled or categorized by either a human coder or an automated labelling process)
3. Select which ML algorithms will be used for the computer to learn patterns within the labelled data training set
4. Allow the algorithms to predict a test set of data that has also been labelled to evaluate how well the algorithms can guess the pre-labelled test set.
Semantic Topic Tagging
As an applied example for understanding what topics are being discussed in a body of text using a supervised machine-learned for classification method, we have semantic topic-tagging, which is another cutting edge technique and it's “the extraction and disambiguation of entities and topics mentioned in or related to a given text.”
Semantic topic tagging involves recognition that humans have already pre-labelled large numbers of topic (called concepts within semantic tagging) in public Web repositories, such as Wikipedia.
Example:
Barack Obama has a Wikipedia entry, and that entry lists a lot of description about who Barack Obama is, how he grew up, his political career, etc. What supervised machine-learning can do, is it can take all of those words in that description of the Wikipedia entry for Barack Obama and it can say, this is my pre-labeled crowd-sourced text upon which I can use in the future to predict if people are talking about Barack Obama in the text without even mentioning necessarily his name.
Supervised machine learning is taking intelligence that we have from before and then applying that to predict various things in the future.
One of the most common tasks for supervised machine learning is this task of classification, which is the process of applying meaningful labels to data to help make sense of that data. Supervised machine leaning for classification can be applied to text, especially when the goal is to classify (or categorize) text according to a predefined goal.
Supervised ML for classification
Steps for supervised ML for Classification (Text, in particular)
1. Identify required data and pre-process the data (tokenization, normalization, etc.)
2. Determine which part of the data will be used as the training set from which the computer learns patterns (each data point must be labelled or categorized by either a human coder or an automated labelling process)
3. Select which ML algorithms will be used for the computer to learn patterns within the labelled data training set
4. Allow the algorithms to predict a test set of data that has also been labelled to evaluate how well the algorithms can guess the pre-labelled test set.
Semantic Topic Tagging
As an applied example for understanding what topics are being discussed in a body of text using a supervised machine-learned for classification method, we have semantic topic-tagging, which is another cutting edge technique and it's “the extraction and disambiguation of entities and topics mentioned in or related to a given text.”
Semantic topic tagging involves recognition that humans have already pre-labelled large numbers of topic (called concepts within semantic tagging) in public Web repositories, such as Wikipedia.
Example:
Barack Obama has a Wikipedia entry, and that entry lists a lot of description about who Barack Obama is, how he grew up, his political career, etc. What supervised machine-learning can do, is it can take all of those words in that description of the Wikipedia entry for Barack Obama and it can say, this is my pre-labeled crowd-sourced text upon which I can use in the future to predict if people are talking about Barack Obama in the text without even mentioning necessarily his name.
